This section is part of the Infineon Aurix Project 2020
The machine learning section of the project had the goal of transpile the regressor model trained in Python and bring it in C-code, to run inference on the board. The starting point was a regression model generated using scikit-learn (or sklearn), with few steps of pre-processing and training.
Sklearn groups together the steps of the overall model in the so-called Pipeline. So the first thing to do is to split the Pipeline into separate steps and to generate intermediate data. Then the question was “How could I bring this Python code in C?”.

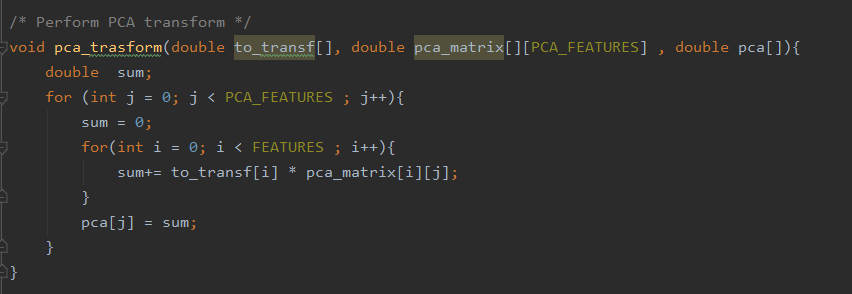
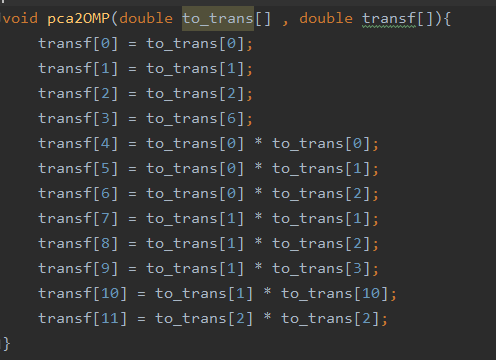
I started studying the preprocessing steps from a mathematical point of view, extracting the mean and standard deviation of features to normalize each data with a StandardScaler and then I performed a Principal Component Analysis (PCA). I didn’t know exactly how the PCA algorithm could bring the data from one to another representation space, but I knew that PCA is a linear combination of features, so it had to exist a transformation matrix that, when multiplied to the original vector of data, could extract the principal components. I was able to find the entries of this matrix into the attributes of the PCA, so in C the transformation became a matrix multiplication. I transformed once again the principal components in polynomial features, for better performance.
Then the challenge was to take the regressor model in Python and bring it to C.
A regressor is something like a function y=f(x) that receives as input the multi-dimensional data x to analyze and then performs a prediction, generating a real scalar value y. If the model is linear, in C this could be implemented as a linear combination of each feature plus a constant value. The coefficients associated with every term and the intercept value are the attributes of the linear model, so we can extract them and build a C function that makes the dot product of coefficients and features and adds the intercept. I used a Python third-party library, M2Cgen, that made this for me.
Thanks to these steps I was able to run inference in C, without C-third-party libraries or expensive operations, just addition and multiplication.

The model I transpiled to C received as input a vector of 120 components: in some situations, this could be too expensive in terms of memory usage and becomes unacceptable when we have to store a large amount of data before sending them to a client. So I thought: “How could I reduce the memory usage and computational effort?”. I have tried different types of models and I found that an SGD-Regressor didn’t use 44 of the 120 input, choosing zero-coefficients for them, so these features could be simply not stored in memory. But my researches does not stop: I trained an Orthogonal Matching Pursuit model, finding that it uses just 10% of the features (so 12/120), with absolutely comparable performance. A great saving of memory and computation!
After bringing the model in C, the problem was: “How the data should arrive from a client to the board?”. I wrote a simple Python script that serializes the raw-data vector and sends it to a socket, using TCP protocol. The data were delivered in a fast and reliable way. I was able to make a C-program and a Python-script communicate, to start inference of a regression model in C, but now this should bring to the board.
I sent all of this code to my teammates, that dealt with the TCP-IP stack implementation and integrated onboard these developed features.