This section is part of the Infineon Aurix Project 2020
One of the main features needed for our project is intercommunication via Ethernet. This allows us to exchange data with a host PC or other devices and analyze them onboard.
For our implementation, due to the limited memory resources available on the device, we decided to rely on lwIP (lightweight IP), an open-source TCP/IP stack designed for embedded systems. Its focus is to reduce resource usage while still having a full-scale TCP stack and it could be used in bare metal, without the necessity of an OS and directly relying on the data-link layer. So, it seemed to us the best choice.
Since there were neither recent nor working versions for our board, we decided to port it from scratch, counting on IFX libraries for the lower network layers and choosing as target version the last lwIP stable one, the 2.1.2 released at the end of the 2018.
In order to achieve this goal, the main aspect to consider is the writing of the configuration. The first major problem to solve was dealing with the pinout configuration: even though in debug mode the board seemed to work correctly, in standalone mode the Ethernet port initialization caused crashes.
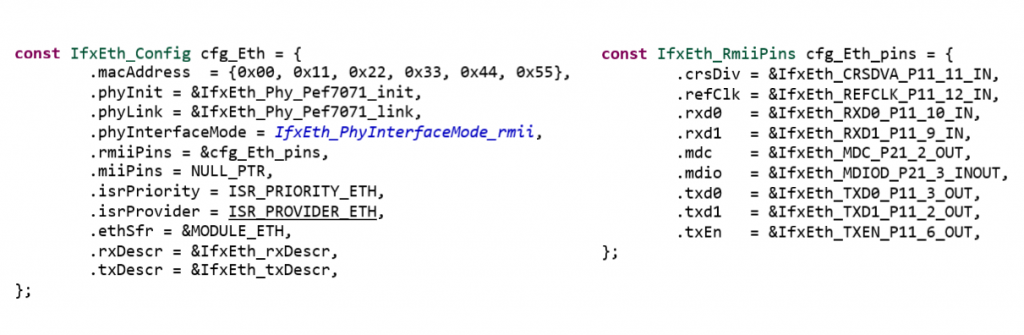
Thanks to the lwIP porting, we can have full access to UDP and TCP API, both with application and raw connections, and other functionalities such as DNS and the more important DHCP support, in order to simply use the Infineon TC297 without bothering configurations on the device itself or on an external router.
Regarding the connection with other devices, we decided to start with the default TCP Echo library and edit it according to our needs. The board works as a server, accepting data both from local and remote networks, while the clients themselves only need to packet information in a predefined structure with a certain behavior. In our implementation, one core is dedicated to the ethernet intercommunication, while the other two’s scope is the bare elaboration and visualization on the display, thanks to the GLCD and ML libraries.
The data exchange and elaboration process can be divided in three different phases.
- Each client starts the communication by sending its own autogenerated ID, which identifies itself, and the size of raw data that should be elaborated.
- If the server is able to allocate the needed space, the data exchange begins and all results are bound to that specific client. In this way, a bunch of samples for the machine learning predictions is sent to the board and all data are elaborated in parallel, thanks to the multicore library. Moreover, thanks to the latter together with the client IDs, we can afford multiple client connections and visualized machine learning results on the screen using different colors, one corresponding to each client ID.
- Finally, when all instances results are elaborated, these are sent back to the client, that can decide to instantiate a new “connection slot” and proceed with other data or simply close the connection with the server.